G3D
G3D dataset contains a range of gaming actions captured with Microsoft Kinect. The Kinect enabled us to record synchronised video, depth and skeleton data. The dataset contains 10 subjects performing 20 gaming actions: punch right, punch left, kick right, kick left, defend, golf swing, tennis swing forehand, tennis swing backhand, tennis serve, throw bowling ball, aim and fire gun, walk, run, jump, climb, crouch, steer a car, wave, flap and clap.
The 20 gaming actions are recorded in 7 action sequences as shown in Table 1. Most sequences contain multiple actions in a controlled indoor environment with a fixed camera, a typical setup for gesture based gaming. Each sequence is repeated three times by each subject as shown in Table 2.
Formats
Due to the formats selected, it is possible to view all the recorded data and metadata without any special software tools. The three streams were recorded at 30fps in a mirrored view. The depth and colour images were stored as 640x480 PNG files and the skeleton data in XML files.
For each sequence we have recorded each frame as colour, raw depth and depth transformed to colour co-ordinates in PNG format (see Figure 1). The raw depth information contains the depth of each pixel in millimetres and was stored in 16-bit greyscale and the raw colour in 24-bit RGB. The depth information was also mapped to the colour coordinate space and stored in a 16-bit greyscale. The 16-bits of depth data contains 13 bits for depth data and 3 bits to identify the player. The player index can be used to segment the depth maps by user (see Figure 2).
 |
 |
 |
 |
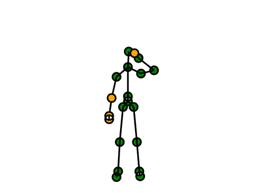
In addition we have recorded skeleton data for each frame in XML format. The root node in the XML file is an array of skeletons to allow for future versions of the dataset to include multiple subjects. Each skeleton contains the player’s position and pose. The pose comprises 20 joints as defined by Microsoft. The player and joint positions are given in X,Y and Z co-ordinates in meters. These positions are also mapped into the depth and colour co-ordinates spaces. The skeleton data includes a joint tracking state, displayed in Figure 3 as tracked (green), inferred (yellow) and not tracked (red).
 |
Download
We make the data available to the researchers in computer vision community, the only requirement for using G3D is to cite our paper:
V. Bloom, V. Argyriou and D. Makris, "Hierarchical transfer learning for online recognition of compound actions", Computer Vision and Image Understanding, vol. 144, pp. 62-72, 2016.
On the table below, you can click on the links to download the data for the corresponding action sequence. Each zip file contains 30 folders corresponding to 10 actors repeating each action 3 times. Each of these folders contains 4 folders corresponding to colour, raw depth, transformed depth and skeleton files. The action point annotations can be downloaded from here.
| Scenarios | Size | Actions |
| Fighting | 7.3GB | Right Punch |
| Left Punch | ||
| Right Kick | ||
| Left Kick | ||
| Defend | ||
| Golf | 4.2GB | Golf swing |
| Tennis | 5.9GB | Swing forehand |
| Swing backhand | ||
| Tennis serve | ||
| Bowling | 2.9GB | Throw bowling ball |
| First Person Shooter | 14GB | Aim & shoot gun centre |
| Aim & shoot gun right | ||
| Aim & shoot gun left | ||
| Walk | ||
| Run | ||
| Jump | ||
| Climb | ||
| Crouch | ||
| Driving a car | 6.6GB | Hold steering wheel |
| Turn right | ||
| Turn left | ||
| Miscellaneous | 5.8GB | Wave |
| Flap arms | ||
| Clap |
| Actor | Fighting | Golf | Tennis | Bowling | FPS | Driving | Misc | ||||||||||||||
| 1 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33* | 34 | 35 | 36 | 37 | 38 | 39 | 40 | 41 | 42 |
| 2 | 43 | 44 | 45 | 46 | 47 | 48 | 49 | 50 | 51 | 52 | 53 | 54 | 55 | 56 | 57 | 58 | 59 | 60 | 61 | 62 | 63 |
| 3 | 64 | 65 | 66 | 67 | 68 | 69 | 70 | 71 | 72 | 73 | 74 | 75 | 76 | 77 | 78 | 79 | 80 | 81 | 82 | 83 | 84 |
| 4 | 85 | 86 | 87 | 88 | 89 | 90 | 91 | 92 | 93 | 94 | 95 | 96 | 97 | 98 | 99 | 100 | 101 | 102 | 103 | 104 | 105 |
| 5 | 106 | 107 | 108 | 109 | 110 | 111 | 112 | 113 | 114 | 115 | 116 | 117 | 118 | 119 | 120 | 121 | 122 | 123 | 124 | 125 | 126 |
| 6 | 127 | 128 | 129 | 130 | 131 | 132 | 133 | 134 | 135 | 136 | 137 | 138 | 139 | 140 | 141 | 142 | 143 | 144 | 145 | 146 | 147 |
| 7 | 148 | 149 | 150 | 151 | 152 | 153 | 154 | 155 | 156 | 157 | 158 | 159 | 160 | 161 | 162 | 163 | 164 | 165 | 166 | 167 | 168 |
| 8 | 169 | 170 | 171 | 172 | 173 | 174 | 175 | 176 | 177 | 178 | 179 | 180 | 181 | 182 | 183 | 184 | 185 | 186 | 187 | 188 | 189 |
| 9 | 190 | 191 | 192 | 193 | 194 | 195 | 196 | 197 | 198 | 199 | 200 | 201 | 202 | 203 | 204 | 205 | 206 | 207 | 208 | 209 | 210 |
| 10 | 214 | 215 | 216 | 217 | 218 | 219 | 220 | 221 | 222 | 223 | 224 | 225 | 226 | 227 | 228 | 229 | 230 | 231 | 232 | 233 | 234 |
*Please note sequence 33 was corrupted and is therefore not available for download at this time.
For any queries related to the dataset please email Dr Victoria Bloom