ViHASi:
Virtual Human Action Silhouette Data
for the Evaluation of
Silhouette-Based Action Recognition Methods
and
the Evaluation of
Silhouette-Based Pose Recovery Methods (NEW)
last updated on the
13th of January 2009
Part of the REASON project funded by the UK's Engineering and Physical Sciences Research Council (EPSRC)
This dataset has been put together by the project's team based at Kingston University's Digital Imaging Research Centre
NEWS: We have also made our real-world
action video data available online, including a large number of manually
annotated silhouettes (visit our
MuHAVi-MAS page)
NEWS:
The corresponding paper including detailed description of the data and
experimental methodology has been accepted, here is the citation information:
H. Ragheb, S. Velastin, P.
Remagnino and T. Ellis,
"ViHASi: Virtual Human Action
Silhouette Data for the Performance Evaluation of Silhouette-Based Action
Recognition Methods", the Workshop on Activity Monitoring by Multi-Camera
Surveillance Systems,
September 11, 2008, Stanford University, California, USA, to appear.
Abstract
We provide a large body of
synthetic video data generated for the purpose of evaluating different
algorithms on human action recognition which are based on silhouettes. The data
consist of 20 action classes, 9 actors and up to 40 synchronized perspective
camera views. It is well known that for the action recognition algorithms which
are purely based on human body masks, where other image properties such as
colour and intensity are not used, it is important to obtain accurate silhouette
data from video frames. This problem is not usually considered as part of the
action recognition, but as a lower level problem in the motion tracking and
change detection. Hence for researchers working on the recognition side, access
to reliable Virtual Human Action Silhouette (ViHASi) data seems to be both a
necessity and a relief. The reason for this is that such data provide a way of
comprehensive experimentation and evaluation of the methods under study, that
might even lead to their improvements.
Introduction
We propose to utilize a virtual
environment and produce valuable synthetic video data for the purpose of
evaluating a class of action recognition methods. These are the silhouette-based
human action recognition (SBHAR) methods. Such virtual action samples allow us
to evaluate the strengths and weaknesses of any SBHAR method by performing a
variety of quantitative experiments under controlled conditions. After
describing the data in details, we briefly outline examples of experiments which
might be considered not only to evaluate a SBHAR method on its own but also to
compare it with alternatives.
The virtual environment used here to produce the data is the MotionBuilder
software. This software, which has mainly been developed for animation and film
industry, provides useful tools and facilities towards producing synthetic
videos. In this 3-dimensional (3D) environment, users can select or import
characters (actors), skeletal motions (actions) and other elements needed in
their scenarios to create their required story. Further, one can define
unlimited number of camera views from which the videos can be rendered. The
video frame rate and the video file format can be selected from a list of options. The
start and end frame could be different from those corresponding to each of the
whole motions used.
We make the data available to the researchers in computer vision community
through a password protected server at the Digital Imaging Research Centre of
the Kingston University London. The data may be accessed by sending an Email
(subjected "ViHASi Data") to Prof Sergio A. Velastin at
sergio.velastin@ieee.org
giving the names of the researchers who wish to use the data and their main
purposes. The only requirement for using the ViHASi data is to refer to this
site in the corresponding publications.
ViHASi Data Details
We use the MotionBuilder
software to generate videos of 20 different virtual actions (see Table1 and Fig.
3) performed by 9 different virtual actors (see Table2 and Fig. 1). These actions
are
captured at 30 fps with resolution 640x480 and using a variety of virtual
cameras with up to 40 different viewing directions (see Table3 and Fig. 2). Each
action class provides identical action motions and durations for all actors.
These motion data correspond to the actions performed previously by human actors
using optical or magnetic motion capture (mocap) hardware so that skeletal
motions could be collected with reasonable precision. For each actor, we create
20 action sequences per camera using the mocap data that come with the software. The names
and numbers (C1 to C20) of these action classes are listed in Table 1 together
with the corresponding number of video frames. However anyone using our approach
can use other mocap data, an important facility that we are planning to utilize
in the future. We use some alternative 3D actors in addition to those provided
by the software. These 3D actors, shown in Fig. 1, consist of very detailed 3D
structures including skeleton, skin, cloth and face components giving realistic
simulations of humans.

Figure 1. Images of the virtual actors
to which the virtual motions are applied to generate virtual actions.
As shown in Fig. 2, our 40
synchronized perspective cameras consist of two sets of 20 camera views. The
cameras are located around two circles in a surround configuration where camera
numbers are assigned in the anti-clockwise direction starting with V1 and V21.
All cameras are directed towards an identical central point (called O in Fig.
2), i.e. the projection of the centre of the circles on the floor. All viewing
directions in each camera set have an identical slant angle with the horizontal
plane. The slant angle for the first set (cameras V1 to V20) is about 27 degrees
while for the second set (cameras V21 to V40) the slant angle is 45 degrees.
Neighbouring cameras in each set have a tilt angle of about 18 degrees with each
other. The rotation angle of each camera around its optical centre is zero, so
that an actor who is standing on the central point appears vertical from all
camera views. The distances between cameras and the centre point O are set so that
all of the actions are seen from all camera views for their whole durations. An
identical distance is set for cameras V1 to V20 while another identical distance
is set for cameras V21 to V40. We do not provide the calibration matrices for
our cameras. However these cameras may be calibrated, if required, for instance
using a silhouette-based calibration method.
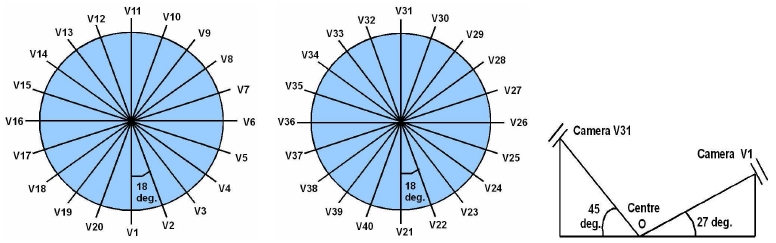
Figure 2. Camera configurations: top
view of the first set of 20 cameras (left), and the second set of 20 cameras
(middle); side view of sample cameras V1 from the first set and V31 from the
second set (right).
On the table below, you can click on the links to download the data for the
corresponding action, or you can click here (150 MB) to download
the complete set.
The Motion
Capture data (3D pose data in BVH format) corresponding to all actions
performed by the actor A1 (Humanoid) can be downloaded
here (486 KB). NEW
We are planning to provide the 2D
ground-truth images of joint positions (2D pose data) corresponding to the
silhouettes (to appear here as soon as completed).
| action class |
action name |
length
(frames) |
Table 1. Action class names as appearing in the ViHASi
data folders and corresponding numbers
for the 20 virtual motions which are applied to the 9 virtual actors of Fig. 1;
the number of video frames (at 30 fps) for each class is also given.
It is straightforward in MotionBuilder to extract the silhouettes corresponding to the bodies of actors at
each frame, an advantage of virtual world that is hardly possible in
real world. Having extracted accurate silhouettes of so many action samples, one
can evaluate the performance of SBHAR methods in a more controlled manner. We
plan to complete generating the remaining branches of the data and extending its
coverage. So far, we have generated videos by applying the 20 classes of action
mocap data a) to 2 actors (A1 and A2) and capturing from all 40 camera views (V1
to V40), b) to another 4 actors (A3, A4, A5, A9) and capturing from 12 camera
views from the first camera set (V1, V3, V4, V6, V8, V9, V11, V13, V14, V16, V18,
V19), and c) to another 3 actors (A6, A7, A8) and capturing from 12 camera views
from the second camera set (V21, V23, V24, V26, V28, V29, V31, V33, V34, V36, V38,
V39). Note that actor A1 is a humanoid suitable to be used as the main actor in the
training data. Also, our actors provide both male and female body shapes
together with a variety of clothes. Further the most recent actor we have added
is a kid (A9) that might provide more challenging motion patterns compared to
the adult
actors. Fig. 3 shows sample images taken from each of the 20 action classes
listed in Table 1 and performed by the actor A4. Finally, Tables 2 and 3 provide
the corresponding names as appear in the ViHASi data folders together with
the symbols used here to refer to them.

Figure 3. Sample video frames (using
the actor A4 and camera V1) taken
from each of the 20 action classes (C1, C2, ..., C20) as per Table 1.
Table 2. Actor full names as appear in the ViHASi
data folders and the corresponding symbols used in Fig. 1.
| camera symbol |
camera name |
camera symbol |
camera name |
Table 3. Camera full names as appear in the ViHASi
data folders and the corresponding symbols used in Fig. 2.
Suggested Experiments
For all experiments performed
using synthetic data, the number of action classes should be set to the maximum,
i.e. 20, while the number of training cameras and actors may vary in
different cases. Different experiments may be designed to evaluate specific
behaviour of the SBHAR method under study depending on the samples included in the training data and
the ones included in the test data.
These experiments include but are not limited to: a) Leave-One-Out Cross
Validation; b) Identical Train and Test Actors with Novel Test Cameras; c)
Identical Train and Test Cameras with Novel Test Actors; and d) Novel Test
Actors with Novel Test Cameras. For each experiment the results should contain:
the overall recognition rate; the total number of misclassifications out of the
total number of test video samples; a table for the number of misclassifications
per action class out of the number of test samples belonging to that class; a
table for the number of misclassifications per actor out of the number of test
samples belonging to that actor; a table for the number of
misclassifications per camera out of the number of test samples belonging to that camera.
Similar experiments may be
repeated for the test videos: a) corrupted by noise, for instance by adding
salt-and-pepper noise with a variety of noise densities; and b) corrupted by
partial occlusions, such as vertical and horizontal bars or similar measurable
occlusions. Sample original and corrupted silhouettes are shown in Fig. 4
for two different camera views and the same frame.
Finally, an experiment to test
the capability of temporal segmentation algorithms in conjunction with a SBHAR
method, is to concatenate all action videos corresponding to a single camera and
a single actor, and test this long sequence (where training data do not include
any of these test samples). Although here there is no natural transitions
between different action classes, this is still a challenging experiment that is
worth trying.

Figure 4. Sample silhouettes of the
action class KnockoutSpin (C11) captured using two camera views V1
and V6 (left) and the corresponding corrupted images by adding 40%
salt-and-pepper random noise (middle) and partial occlusions, using 6 and 8
pixels vertical and horizontal bars, to fragment silhouettes (right).